Complément réseau RIP : algorithme de Bellman-Ford¶
Nous avons vu dans le cours que le protocole de routage RIP est basé sur un algorithme de recherche de plus court chemin dans un graphe qui est appelé du nom de ses créateurs : l'algorithme de Bellman-Ford. Tout comme l'algorithme de Dijkstra, il permet de déterminer un plus court chemin dans un graphe (orienté ou non) mais contrairement à l'algorithme de Dijkstra il autorise l'utilisation de poids négatifs. Nous allons maintenant voir plus en détail cet algorithme.
L'algorithme en pseudo-langage :
#Notations :
#G est un graphe ayant N sommets et S un sommet "de départ"
#V désigne tout sommet du graphe
#phi est une matrice formée telle que phi[i,V] = valeur d'un plus court chemin de S à V en au + i arcs
fonction bellman-ford (G,S) {
#initialisation
Pour i de 0 à N-1 {
phi[i,v] = +oo #on met toutes les distances à +oo
}
Pour i de 0 à N-1 {
phi[i,S] = 0 #on met les distances de S à S à 0
}
#calcul de la matrice phi
Pour i de 1 à N-1 {
Pour tout sommet v de G {
Pour tout prédécesseur u de v {
Si phi[i,v] > phi[i-1, u] + poids(u,v) {
phi[i,v] = phi[i-1, u] + poids(u,v)
}
}
}
}
retourner phi
}
La complexité de l'algorithme est en $\displaystyle O{(|S||A|)}$ où $|S|$ est le nombre de sommets et $|A|$ est le nombre d'arcs. En comparaison, l'algorithme de Dijkstra est en $\displaystyle{ O((|A|+|S|)\times \log(|S|))}$, elle est donc bien meilleure. On peut améliorer légérement la complexité de l'algorithme en arrêtant la boucle principale si les distances sont inchangées d'une étape à la suivante, mais ça ne change pas la complexité dans le pire des cas.
Dans la pratique, ce n'est pas la matrice phi qui nous interesse mais uniquement la dernière ligne de cette matrice.
Faisons un exemple pour expliquer l'algorithme :
Cherchons le plus court chemin pour aller de A à E dans le graphe suivant :
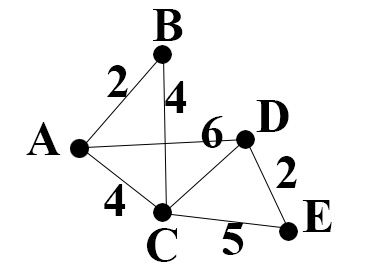
On notera : P l'ensemble des prédécesseurs d'un sommet (ce graphe n'est pas orienté donc P est aussi l'ensemble des voisins dans ce cas, mais c'est un cas particulier et l'algorithme fonctionne tout aussi bien avec des graphes orientés). Par exemple, dans notre cas, P(B) = {A, C}, P(C) = {A, B, D, E}, etc.
Le but est de construire la matrice notée phi dans l'algorithme. Normalement on partirait d'une matrice dont toutes les valeurs seraient $+\infty$ et on mettrait à jour chaque ligne à chaque itération de l'algorithme. Cette présentation n'étant pas pratique, nous allons compléter la matrice ligne par ligne, une ligne représentant une itération de l'algorithme. On commence donc par la phase d'initialisation.
Initialisation :
On commence par mettre $+\infty$ sur toute la 1ère ligne, sauf pour A (la distance de A à A étant 0).
| A | B | C | D | E |
|---|---|---|---|---|
| 0 | +oo | +oo | +oo | +oo |
Calcul de phi :
N = 5 donc il y aura 4 itérations.
1ère itération :
On prend le 1er sommet qui n'est pas A dans notre matrice, c'est à dire B. On sait que B a 2 prédécesseurs A, C et D ce qui signifie que pour venir en B, on peut venir de A, C ou D. Sur la ligne précédente, la distance de A à C est $+\infty$ (et la distance de A à A est 0). 0 + poids(A-B) = 2 et $2 < +\infty$ donc on peut mettre à jour la distance de A à B en remplaçant $+\infty$ par 2 (et on peut aussi écrire d'où on vient, donc A dans ce cas). Par contre venant de C la distances étant de $+\infty$, elle ne sera pas inférieure à 2 donc on laisse B à 2.
On refait le même raisonnement avec les autres sommets.
Avec le sommet C : ses prédécesseurs sont A, B, D et E. À la ligne précédente, la distance de A à A est 0 et 0 + poids(A-C) = $4 < +\infty$ donc on met à jour la distance de A à C en notant 4 (et on indique A). Les distances de A à B, de A à D et de A à E étant toutes $+\infty$, elles ne seront pas inférieures à 4 donc on laisse C à 4.
En continuant jusqu'à E, on obtient donc :
| A | B | C | D | E |
|---|---|---|---|---|
| 0 | +oo | +oo | +oo | +oo |
| 0 | 2(A) | 4(A) | 6(A) | +oo |
2ème itération :
On repart du sommet B. Le sommet B a 2 prédécesseurs : A et C. La distance de A à A est 0 et la distance de A à C est 4 et 4 + poids(A-C) = $8 > 2$ donc on ne met pas à jour la distance de A à B venant de C.
Avec le sommet C : le sommet C a 4 prédécesseurs A, B, D et E. Les distances venant de A sont respectivement 0, 2, 6 et $+\infty$ donc la meilleure reste évidement celle qui vient de A donc on laisse C à 4.
Avec le sommet D : D a 3 prédécesseurs : A, C et E. Les longueurs venant de A sont respectivement 0, 4 et $+\infty$. La longueur de A à D est 6. Mais 4 + poids(C-D) = $5 < 6$ donc on met à jour la distance de A à D en remplaçant 6 par 5 (et on vient donc de C).
Avec le sommet E : E a 2 prédécesseurs : D et C. Les distances venant de A sont respectivement 4 et 6. 4 + poids(C-E) = 9 $< +\infty$ donc on met à jour la distance de A à E qui est donc 9. Mais 6 + poids(D-E) = $8 < 9$ donc on met à jour la distance de A à E qui est donc 8. On obtient donc :
| A | B | C | D | E |
|---|---|---|---|---|
| 0 | +oo | +oo | +oo | +oo |
| 0 | 2(A) | 4(A) | 6(A) | +oo |
| 0 | 2(A) | 4(A) | 5(C) | 8(D) |
3ème itération :
Cette fois, on ne détaille pas le principe qui reste le même à chaque étape, on obtient alors :
| A | B | C | D | E |
|---|---|---|---|---|
| 0 | +oo | +oo | +oo | +oo |
| 0 | 2(A) | 4(A) | 6(A) | +oo |
| 0 | 2(A) | 4(A) | 5(C) | 8(D) |
| 0 | 2(A) | 4(A) | 5(C) | 7(D) |
4ème itération : la dernière
On constate que cette itération ne modifie par la ligne précédente. On obtient :
| A | B | C | D | E |
|---|---|---|---|---|
| 0 | +oo | +oo | +oo | +oo |
| 0 | 2(A) | 4(A) | 6(A) | +oo |
| 0 | 2(A) | 4(A) | 5(C) | 8(D) |
| 0 | 2(A) | 4(A) | 5(C) | 7(D) |
| 0 | 2(A) | 4(A) | 5(C) | 7(D) |
L'algorithme est terminé. On constate alors que, par exemple, le plus court chemin de A à E est de 7 et on l'obtient facilement par lecture de la matrice "à l'envers" : E - D - C - A ce qui donne donc : A - C - D - E.
Remarques :
On peut mettre aussi comme condition d'arrêt que si 2 lignes restent identique, ce n'est pas la peine de continuer l'algorithme.
Cet algorithme fonctionne exactement de la même façon avec des graphes orientés et même avec des poids de valeurs négatives.
À vous de "jouer"...¶
En utilisant l'algorithme de Belman-Ford déterminer le plus court chemin de 1 à 7 dans le graphe suivant :

Il ne reste plus qu'à implémenter l'algorithme en Python... Vous pouvez reprendre la classe Graphe qui nous a servi à implémenter l'algorithme de Dijkstra puis ajouter les méthodes qui serviront pour cet algorithme comme par exemple poids(une arête) ou encore predecesseurs(un sommet).